Batch processing template code
Software Engineer at BMW, Oracle Certified Professional Java SE 11 Developer
Batch processing refers to the execution of a series of tasks or operations on a large volume of data in a batch. I used batch processing in the past for following use cases.
Use cases
- Perform batch insertion of large data into a database table
- Query large amounts of data in batches from an API which has a query limit
Why should I use batch processing
Performing small, fast transactions is generally preferred over large, long-running transactions for several reasons.
- Locking: Long-running transactions acquire locks on affected rows or tables, preventing other transactions from accessing or modifying the same data until the locks are released. This can decrease concurrency, cause delays, and impact performance.
- Resource consumption: Long-running transactions consume significant resources like memory and disk space. As the transaction progresses, the database may need to allocate more resources to handle the workload, potentially straining system resources and impacting performance.
- Rollback difficulties: Rolling back a long-running transaction in MySQL can be time-consuming. Reverting all the changes made by the transaction may take a considerable amount of time, potentially locking affected tables and impacting database performance and availability.
- Replication delays: Long-running transactions in MySQL replication can cause delays. Replication relies on the transaction log to synchronize changes from the primary database to replicas. Large transactions increase the time needed to process and transmit changes, potentially resulting in replication lag and data inconsistency.
Template code
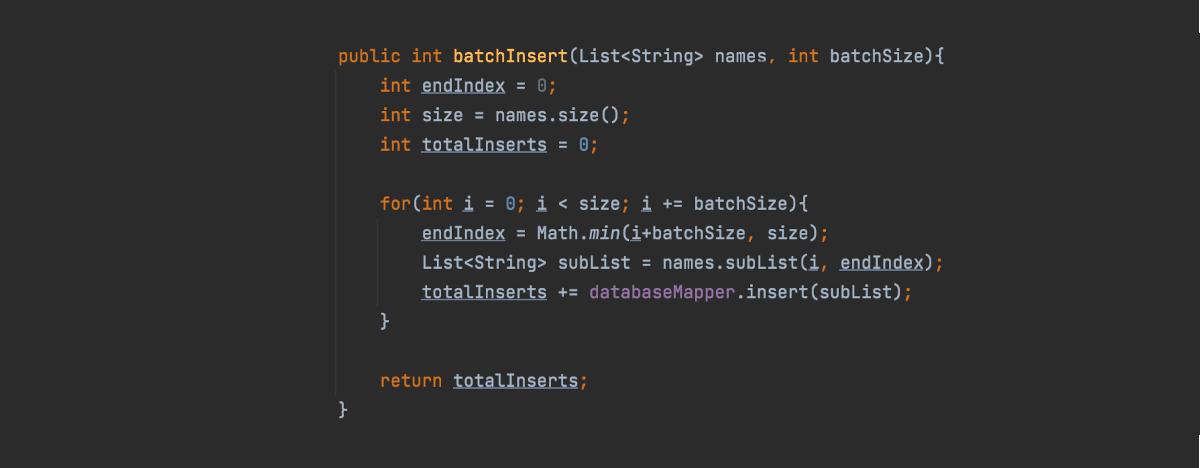
Following example demonstrates batch insertion of a list of names into a database table. Generally, it is preferable to perform small, fast transactions with a transaction time of less than 1s, rather than large, long-running transactions. Therefore, it is always beneficial to utilize batch processing when inserting a large number of rows simultaneously into a database table."
public int batchInsert(List<String> names, int batchSize){
int endIndex = 0;
int size = names.size();
int totalInserts = 0;
for(int i = 0; i < size; i += batchSize){
endIndex = Math.min(i+batchSize, size);
List<String> subList = names.subList(i, endIndex);
totalInserts += databaseMapper.insert(subList);
}
return totalInserts;
}
Test
In our test, we can see that above code inserts the data into 3 batches.
@Test
public void shouldInsert3batches(){
// GIVEN
List<String> names = List.of("Anna", "Berta", "Theodor", "Christian", "Rudolf");
Mockito.when(databaseMapper.insert(List.of("Anna", "Berta"))).thenReturn(2);
Mockito.when(databaseMapper.insert(List.of("Theodor", "Christian"))).thenReturn(2);
Mockito.when(databaseMapper.insert(List.of("Rudolf"))).thenReturn(1);
int batchSize = 2;
// WHEN
int count = testee.batchInsert(names, batchSize);
// THEN
Mockito.verify(databaseMapper, Mockito.times(3)).insert(ArgumentMatchers.anyList());
Mockito.verify(databaseMapper, Mockito.times(1)).insert(List.of("Anna", "Berta"));
Mockito.verify(databaseMapper, Mockito.times(1)).insert(List.of("Theodor", "Christian"));
Mockito.verify(databaseMapper, Mockito.times(1)).insert(List.of("Rudolf"));
Assertions.assertThat(count).isEqualTo(5);
}
Conclusion
The full code example with test can be find on GitHub.
In conclusion, batch processing offers an effective solution for handling large volumes of data. It enables faster and more efficient transactions, making it a valuable tool for tasks such as batch insertion into a database table. By adopting batch processing, developers can enhance the performance and effectiveness of their data operations.




